.jpeg)
a dummys questions on the road to mech interp proficiency
1. what is meant by the vector space of neuron activations in circuits?
>the vector space of neuron activations refers to the mathematical representation of the activations of
neurons in a neural network layer as vectors.
>sub points:
1. each neuron in the layer can be thought of as a basis direction in the vector space of the activations
for that layer.
Activation → Scalar → Set(Activations) forms → Vector.
2. any direction in the activation space can be represented as a linear combination of the basis directions
(individual neurons). So the vector space spans all possible activation patterns of the neurons.
3. directions often correspond to meaningful features that respond to properties of the input. (e.g curves,
textures).
2. how do the polysemantic neurons affect the vector space of neuron activations?
>polysemantic neurons influence the vector space of neuron activations by representing multiple features (which
can even be unrelated features) within a single neuron.
it complicates the interpretation of neural networks as well as affect how they are organized and represented in
the activation space.
1.they do not correspond to unique features; instead they activate for a mixture of unrelated features. making
the activation space a collection which can have distinct directions as well as rather a more complex structure
in which multiple features can overlap within the same neuron
2.polysemanticity is more prevalent for less important features, which may be represented by fewer dimensions in
the embedding space. this leads to a situation where the vector space is not fully utilized for distinct
features, resulting in a less interpretable structure.
3.in datasets with correlated features, neural networks may opt to represent these features with a single neuron
rather than separate neurons. this will complicate the interpretation of activation space.
3. explain bigrams and skip-trigrams
Example Corpus
Consider the following three sentences:
- "I love programming."
- "Programming is fun."
- "I love fun."
Step 1: Extract Bigrams
From the corpus, we can extract the bigrams as follows:
- From "I love programming":
- (I, love)
- (love, programming)
- From "Programming is fun":
- (Programming, is)
- (is, fun)
- From "I love fun":
- (I, love)
- (love, fun)
| Bigram | Count |
|---|---|
| (I, love) | 2 |
| (love, programming) | 1 |
| (Programming, is) | 1 |
| (is, fun) | 1 |
| (love, fun) | 1 |
Step 2: Calculate Bigram Probabilities
Using Maximum Likelihood Estimation (MLE), we calculate the probabilities:
Step 3: Extract Skip Trigrams
| Skip Trigram | Count |
|---|---|
| (I, programming) | 1 |
| (Programming, fun) | 1 |
| (I, fun) | 1 |
Step 4: Calculate Skip Trigram Probabilities
4. Explain the claims using examples:
"Attention heads can be understood as having two largely independent computations: a QK ("query-key") circuit which computes the attention pattern, and an OV ("output-value") circuit which computes how each token affects the output if attended to."
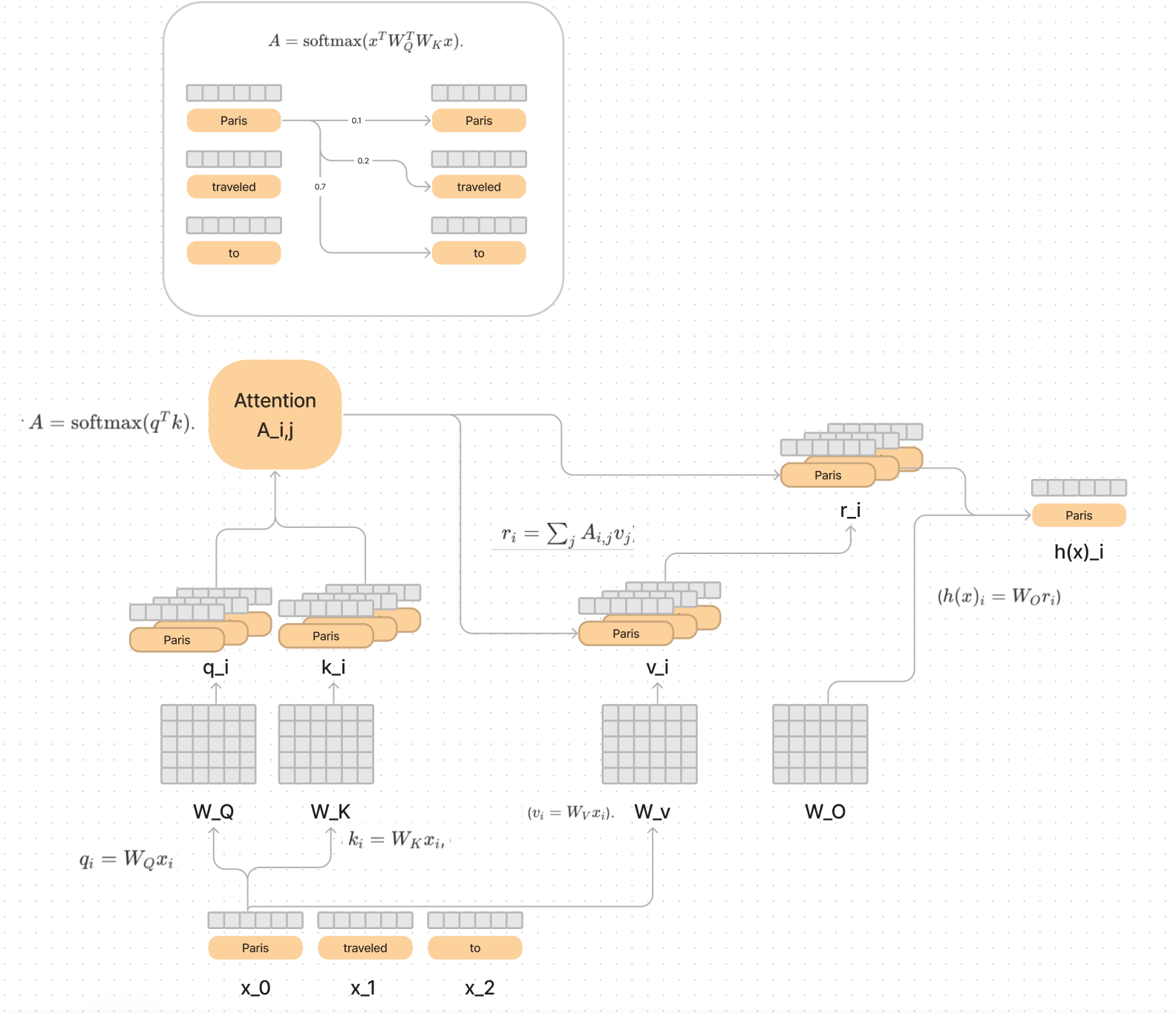
The claims regarding attention heads in transformers can be understood through the concepts of QK (query-key) circuits and OV (output-value) circuits. Each of these circuits plays a distinct role in the attention mechanism, which is fundamental to how transformers process information.
Understanding QK and OV Circuits
1. QK Circuit
The QK circuit is responsible for computing the attention pattern. It determines how much focus one token should place on another token in the input sequence. This is done by calculating the dot product between query vectors (Q) and key vectors (K). The resulting scores indicate the strength of attention that should be applied to each token.
Example:
- Consider a sentence: "The cat sat on the mat."
- Suppose we have a query vector for "cat" and key vectors for all tokens.
- The QK circuit computes the attention scores between "cat" and all other tokens, determining which tokens "cat" should attend to based on their relevance.
2. OV Circuit
The OV circuit computes how each token's value vector (V) contributes to the final output if attended to. After determining which tokens are attended to via the QK circuit, the OV circuit aggregates these contributions to produce the final output vector.
Example:
- Continuing with our previous example, if "cat" attends to "the" and "sat," the OV circuit will combine their value vectors based on the attention scores computed by the QK circuit.
- This combination yields a new representation that reflects the context of "cat" within the sentence.
5. what is meant by the following claim?
"One basic consequence is that the residual stream doesn't have a "privileged basis"; we could rotate it by rotating all the matrices interacting with it, without changing model behavior."
Understanding the Residual Stream
The claim that "the residual stream doesn't have a 'privileged basis'; we could rotate it by rotating all the matrices interacting with it, without changing model behavior" refers to the flexibility and independence of the residual stream in transformer architectures. Here’s a breakdown of what this means, along with examples for clarity.
The residual stream in transformer models acts as a shared memory between layers, where:
Reading from the Residual Stream:
\[ Output = W \cdot ResidualStream \]where W is a weight matrix
Writing to the Residual Stream:
\[ NewResidualStream = PreviousResidualStream + Output \]The "No Privileged Basis" Concept
The claim means that the residual stream's coordinate system is arbitrary and can be transformed without affecting the model's behavior.
Key Properties:
- Arbitrary Basis: Individual coordinates have no inherent meaning
- Rotational Freedom: Any full-rank linear transformation can be applied
Example: 2D Rotation
For a residual stream vector \( r=[x,y] \) and rotation matrix R:
\[ R = \begin{bmatrix} \cos(\theta) & -\sin(\theta) \\ \sin(\theta) & \cos(\theta) \end{bmatrix} \]The transformation:
\[ r' = R \cdot r \] \[ W' = R^{-1}W \]Implications
- Model Consistency: Behavior remains unchanged with uniform transformations
- Interpretability: Dimension importance comes from training, not inherent properties
- Feature Representation: Allows flexible exploration of internal representations